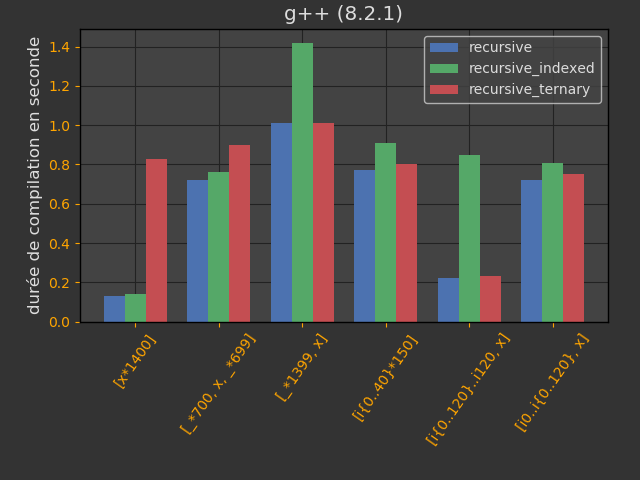
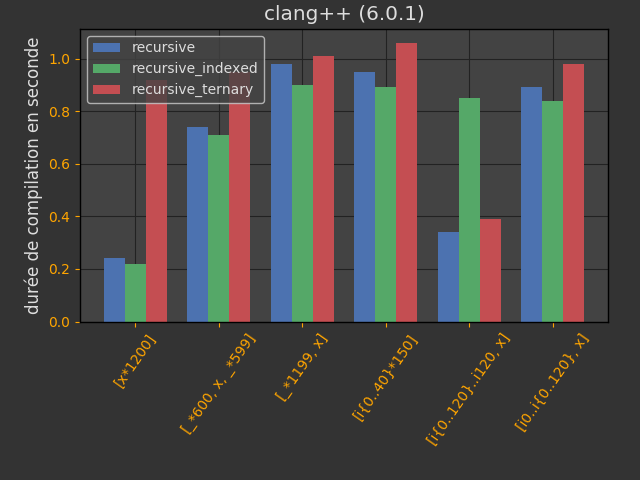
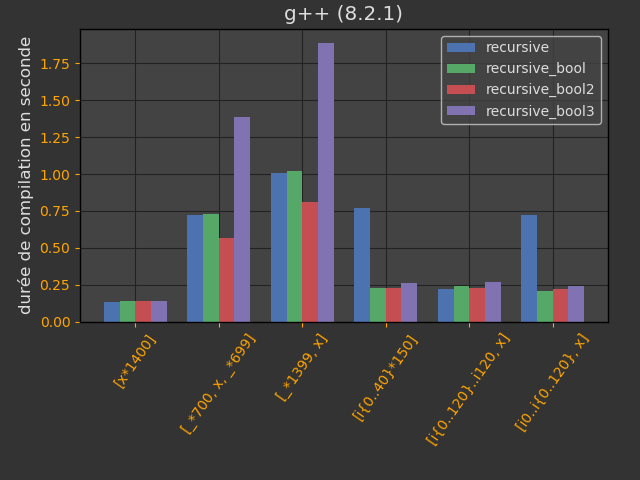
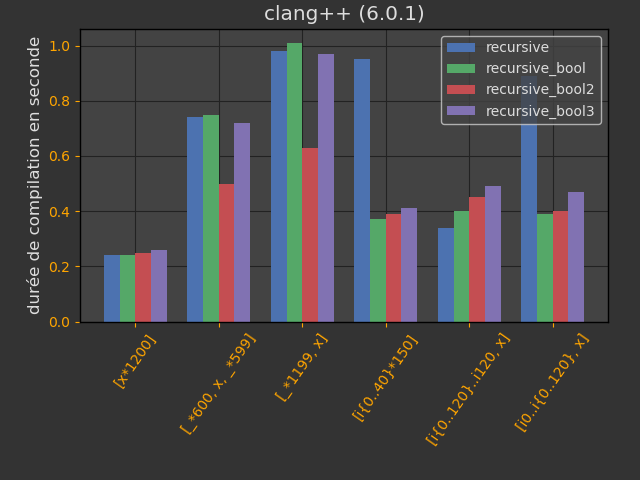
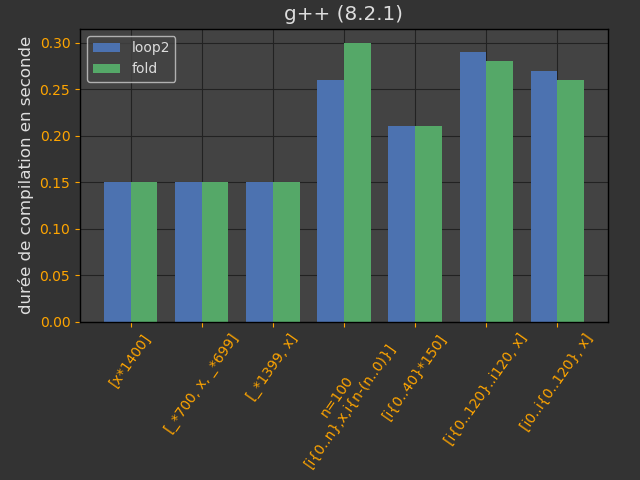
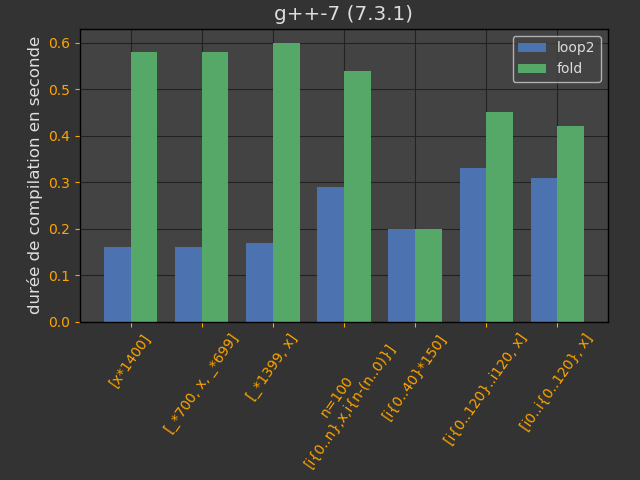
Les opérateurs new et delete
L’allocation dynamique c’est facile: pour un new, un delete
Le quidam du coin.
Pour 12 opérateurs new, 14 opérateurs delete.
La norme de C++11.
Mmmh, va pour 16 opérateurs delete.
C++14.
Finalement 22 opérateurs new et 26 opérateurs delete.
L’apparition de C++17.
Allez, 30 opérateurs delete.
Toujours plus loin avec C++20.
Cet article va parler des opérateurs new et delete. Pas les mots clefs new et delete tout seuls, mais bien de operator new et operator delete de l’en-tête <new>, car derrière les mots clefs usuels se cachent en réalité beaucoup de fonctions surchargées. Soit appelées implicitement par le compilateur, soit explicitement par le développeur en donnant des paramètres à new.
Bien sûr, ce sont des techniques très bas niveau liées à l’allocation dynamique, à moins de vouloir écrire un allocateur global, il est probable que vous n’en ayez jamais besoin. Je vais néanmoins présenter ici les différents opérateurs existant dans le standard et à quel moment ils sont utilisés.
new ou operator new ?
La première chose à faire est de distinguer le mot clef new traditionnellement utilisé de la fonction operator new() se trouvant dans l’en-tête <new>. L’expression new T fait en réalité 2 choses:
- Allouer une zone mémoire en utilisant
operator new(). - Construire le type
Tdans la zone mémoire préalablement allouée (appel du constructeur).
Ces 2 étapes peuvent se faire manuellement en utilisant explicitement un opérateur new suivi d’un placement-new qui appelle un opérateur new spécifique.
new utilise new et 2 operator new, il y a de quoi s’y perdre :).
void* mem = operator new(sizeof(T)); // on alloue une mémoire pouvant contenir un T
T* p = new(mem) T(); // on construit un T dans la zone allouée
// ceci n'effectue aucune allocation dynamique
Il existe la même symétrie avec l’expression delete qui utilise le destructeur suivi d’une libération de la mémoire.
p->~T(); // appel explicite du destructeur
operator delete(p); // libération de la mémoire
Ceci représente le cas de base pour une gestion plus fine de la mémoire. Pour information, c’est une partie de ce qu’utilisent les containers de la STL tel que std::vector à travers les allocateurs (std::allocator). Une partie seulement, car C++17 ajoute un paramètre d’alignement.
Séparation en catégorie
Tous les opérateurs new et presque tous les opérateurs delete sont séparés en 2 catégories: une version tableau et une version sans.
Par exemple void* operator new(std::size_t) et void *operator new[](std::size_t). À part les 4 nouveaux opérateurs delete de C++20, il n’y a pas d’exception.
Il y a néanmoins une différence de comportement avec les operator new[]: La taille nécessaire à leur allocation peut être supérieure à sizeof(T) * len. Il y a un surplus permettant de stocker la taille du tableau et ainsi appeler le bon nombre de destructeurs au moment du delete[]. Cet ajout est automatiquement fait par le compilateur et dépend de son implémentation.
Toute la suite de l’article ne présentera plus les versions tableaux, car le principe derrière est exactement le même que les versions sans tableau.
Plus que 11 opérateurs new et 17 delete :)
Fonctions d’allocation remplaçables
Parmi les opérateurs disponibles, il existe 16 fonctions candidates au remplacement de la fonction d’allocation. C’est-à-dire qu’utiliser new T/new T[n] ou delete p/delete[] p va implicitement faire appel à l’une de ces fonctions que l’utilisateur peut lui-même définir pour changer le comportement par défaut.
La version operator new, en plus du paramètre std::size_t count représentant le nombre d’octets à allouer, prend 2 paramètres optionnels:
std::nothrow_tqui représente l’absence d’exception etstd::align_val_tqui indique l’alignement de l’allocation.
void* operator new(std::size_t count);
void* operator new(std::size_t count, std::align_val_t al);
void* operator new(std::size_t count, const std::nothrow_t&) noexcept;
void* operator new(std::size_t count, std::align_val_t al, const std::nothrow_t&) noexcept;
// plus version new[]
Le paramètre std::nothrow_t s’utilise pour un new de la forme new(std::nothrow) T. Cela ne veut pas dire qu’il n’y aura jamais d’exception (le constructeur de T peut le faire), mais que l’allocation de l’espace mémoire nécessaire ne le fera pas. Si l’allocation échoue, un pointeur nul est retourné.
std::align_val_t fait référence aux types dont l’alignement est supérieur à __STDCPP_DEFAULT_NEW_ALIGNMENT__ et sera alors automatiquement ajouté par le compilateur. Cela dépend des implémentations, mais cette valeur devrait être au moins de la taille du plus grand type disponible, à priori long double.
En supposant que __STDCPP_DEFAULT_NEW_ALIGNMENT__ fait 16, pour utiliser la version new avec alignement, il faudrait un type tel que struct alignas(32) A {};.
Ensuite vient operator delete qui, à la place d’une taille, prend le pointeur à libérer.
void operator delete(void* ptr) noexcept;
void operator delete(void* ptr, std::align_val_t al) noexcept;
void operator delete(void* ptr, const std::nothrow_t&) noexcept;
void operator delete(void* ptr, std::align_val_t al, const std::nothrow_t&) noexcept;
void operator delete(void* ptr, std::size_t sz) noexcept;
void operator delete(void* ptr, std::size_t sz, std::align_val_t al) noexcept;
// plus version delete[]
Et les ennuis commencent. Il y a bien une correspondance 1-1, mais 2 fonctions prenant un std::size_t sz se sont subtilement ajoutées.
Le paramètre sz ajouté en C++14 correspond à la taille de l’objet libéré. Néanmoins, les 2 fonctions avec ce paramètre peuvent ne pas être utilisées pour les types trivialement destructibles ou incomplets. Dans ce cas, ce sont les versions sans ce paramètre qui seront utilisées. Actuellement, gcc utilise bien les fonctions avec le paramètre sz à partir de C++14, mais il faut le forcer avec -fsized-deallocation pour les standards inférieurs. Pour clang, ce flag est requis quel que soit le standard utilisé.
Les versions avec std::nothrow_t sont utilisées lorsque le constructeur de T dans l’expression new(std::nothrow) T jette une exception. Dans ce cas, l’exception est relancée après libération de la mémoire.
Peut-on faire une quelconque différence d’implémentation entre les delete qui prennent des std::nothrow_t et ceux qui ne les prennent pas ? Je ne pense pas, je n’arrive pas à imaginer un tel scénario.
Étrangement, il n’y a pas de prototype qui utilise en même temps sz et std::nothrow_t, alors que l’information de taille pourrait être utilisée pour accélérer certaines désallocations.
Encore 7 opérateurs new et 11 delete.
Placement-new, la construction sans allocation
Le placement-new est ce qui permet de construire un objet depuis une zone mémoire préalablement réservée. Soit via un tableau statique, soit à travers une allocation dynamique.
alignas(T) char buffer[sizeof(T)];
T* p = new(buffer) T; // construction de T
La destruction de cet objet se fait manuellement via un appel direct du destructeur (p->~T()) puis en libérant le buffer si nécessaire.
Cet appel à new correspond au prototype ci-dessous dont l’implémentation est prédéfinie par la bibliothèque standard:
void* operator new(std::size_t count, void* ptr) noexcept;
// + version new[]
Néanmoins, il est possible de surcharger cette fonction pour y introduire n’importe quel paramètre:
void* operator new(std::size_t count, user-defined-args...);
void* operator new(std::size_t count, std::align_val_t al, user-defined-args...);
// + version new[]
count correspond au sizeof de T et la version avec alignement sera automatiquement utilisée si définie et que l’alignement de T dépasse __STDCPP_DEFAULT_NEW_ALIGNMENT__. Dans le cas contraire, le compilateur se rabat sur celle sans alignement.
T* p = new(storage, opt) T; // pourrait correspondre à operator new(std::size_t count, Storage&, StorageOptions)
// et operator new(std::size_t count, std::align_val_t al, Storage&, StorageOptions)
Chacun de ses new a son équivalent delete dans le cas où le constructeur lance une exception.
La version de la bibliothèque standard qui ne fait normalement rien:
void operator delete(void* ptr, void* place) noexcept;
// + version delete[]
Et les surcharges utilisateur:
void operator delete(void* ptr, user-defined-args...);
void operator delete(void* ptr, std::align_val_t al, user-defined-args...);
cppreference.com ne fait pas explicitement mention de la version avec std::align_val_t, mais je l’ajoute pour une meilleure correspondance avec les prototypes de new.
On peut sérieusement se demander à quoi peut servir ces opérateurs prenant n’importe quel type, alors qu’ils pourraient très bien être remplacés par une fonction classique. Une fonction est beaucoup moins tordue que new(a,b,c) T.
Plus que 4 opérateurs new et 9 delete.
Les opérateurs new et delete membre
Jusqu’ici, tous les opérateurs étaient des fonctions libres qui ne peuvent avoir connaissance du type réellement alloué. Il est possible d’avoir cette information en déclarant les opérateurs new et delete en membre statique d’une classe. Les versions membres seront prioritaires à celles libres.
void* T::operator new(std::size_t count);
void* T::operator new(std::size_t count, std::align_val_t al);
void* T::operator new(std::size_t count, user-defined-args...);
void* T::operator new(std::size_t count, std::align_val_t al, user-defined-args...);
// + version new[]
void T::operator delete(void* ptr) noexcept;
void T::operator delete(void* ptr, std::align_val_t al) noexcept;
void T::operator delete(void* ptr, std::size_t sz) noexcept;
void T::operator delete(void* ptr, std::size_t sz, std::align_val_t al) noexcept;
void T::operator delete(void* ptr, args...) noexcept;
// + version delete[]
Le nombre de prototypes est inférieur au nombre de fonctions libres, mais il est tout à fait possible de les réintroduire via les types utilisateurs.
Petite particularité des opérateurs membres: il est possible d’interdire les allocations dynamiques en supprimant la fonction avec void* operator new(std::size_t count) = delete. On peut cependant outrepasser cette restriction en utilisant l’opérateur global avec ::new T.
Bientôt la fin, il ne reste que 4 opérateurs delete.
L’opérateur delete chargé d’utiliser le destructeur
En début d’article, j’indique que la construction d’un objet se fait en 4 étapes représentées par 4 appels de fonctions consécutives:
- Allocation de la mémoire
- Construction de l’objet dans la mémoire allouée
- Appel du destructeur
- Libération de la mémoire
C++20 introduit 4 opérateurs delete qui doivent eux-mêmes faire l’appel du destructeur en plus de la libération.
void T::operator delete(T* ptr, std::destroying_delete_t);
void T::operator delete(T* ptr, std::destroying_delete_t, std::align_val_t al);
void T::operator delete(T* ptr, std::destroying_delete_t, std::size_t sz);
void T::operator delete(T* ptr, std::destroying_delete_t, std::size_t sz, std::align_val_t al);
// pas de version delete[] à cause de l'overhead ajouté par le compilateur pour new[]
On y retrouve al et sz qui suivent les mêmes règles que d’habitude et un type std::destroying_delete_t qui permet une différenciation avec les autres fonctions.
Les raisons de cet ajout sont expliquées dans la proposition P0722 qui corrige les sized-delete avec des classes à taille variable (entre autres).
Pour expliquer le fonctionnement, une classe à taille variable n’est constructible qu’à travers une allocation dynamique de la mémoire ; son allocation contient un surplus de taille contenant la partie variable. Par exemple, une string peut être un segment contenant la taille suivie des chars. Tout cela dans le même segment de donnée. Comme la partie variable n’est pas dans l’objet lui-même, un sizeof de ce type de chaîne correspond à la taille de son seul membre: std::size_t length (par exemple). Les données variables sont ensuite accessibles via reinterpret_cast<char*>(this + 1). On peut retrouver la même chose avec des données variables insérées avant le pointeur de l’objet.
Le problème de ce type de classe apparaît au moment de la libération: comment utiliser l’opérateur delete prenant une taille ou un alignement quand ces 2 informations ne font pas partie du type ? Celui introduit par le compilateur sera erroné. Ou encore, comment récupérer le pointeur d’origine lorsque les données sont insérées avant le type utlisé ?
Dans le premier scénario, une solution (fausse) est de récupérer cette information depuis la fonction void T::operator delete(void* ptr) en castant ptr en type T pour y extraire les informations nécessaires. Malheureusement, ptr représente un T détruit (destructeur utilisé): lire ses membres est invalide.
Pour pallier à tous ces problèmes, les opérateurs delete introduits en C++20 prennent non plus un void* ptr, mais un T* ptr encore valide. C’est pour cette raison que cette fonction doit elle-même appeler le destructeur.
Quant au pointeur alloué, il peut vivre sa vie comme n’importe quel pointeur et être utilisé dans – par exemple – un std::unique_ptr.
Remplacement de l’allocateur global
L’allocateur global est plutôt facile à remplacer, mais seuls les opérateurs considérés comment remplaçables pourront être utilisés de manière transparente. Cela exclut les new/delete avec des variables utilisateurs dont les prototypes doivent être connus par le programme qui les utilise.
Pour ce faire, il suffit de compiler un .cpp qui contient les opérateurs pour en faire soit un .o, soit une bibliothèque. Dans les 2 cas, le bout de code sera compilé dans l’exécutable final.
Dans le cas d’une bibliothèque externe, il est possible de la charger « plus tard » via les méthodes propres à chaque système d’exploitation. Par exemple, les variables d’environnement LD_PRELOAD et LD_LIBRARY_PATH pour Linux.